손실 함수
기계 학습의 손실 함수 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포의 차이나타내는 기능
즉, 이 값이 0에 가까울수록 모델의 정확도가 높고, 반대로 0에서 멀어질수록 모델의 정확도가 낮습니다.
엔트로피
불확실성의 척도입니다. 정보 이론에서 엔트로피는 불확실성을 의미하고 높은 엔트로피는 많은 정보와 낮은 확률을 의미합니다.
불확실성: 어떤 데이터가 나올지 예측하기 어려울 때
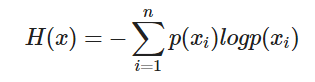
# 예: 동전 뒤집기 & 주사위 굴리기
- 동전을 던질 때 앞면/뒷면의 확률은 1/2로 가정합니다.
- 주사위를 굴린 경우 각 6면 굴림의 확률은 1/6이라고 가정합니다.
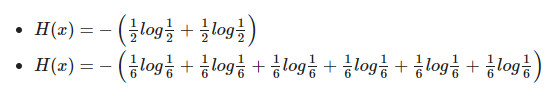
동전의 엔트로피 가치: 0.693
주사위의 엔트로피 값: 1.79
큐브의 엔트로피가 더 높은 것을 볼 수 있습니다.
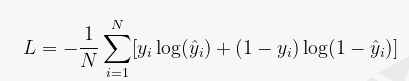
교차 엔트로피 손실은 분류 모델의 손실 함수 그 중 하나로 예측값과 실제값의 차이를 계산하여 모델 학습에 활용한다. 교차 엔트로피 손실은 예측 값이 실제 값에 가까워질수록 감소하는 값입니다.가지다, 손실이 작을수록 모델의 예측 성능이 더 좋습니다.그리고 판단할 수 있습니다.
교차 엔트로피 손실 함수는 종종 분류 모델에서 사용됩니다. 이것은 분류 모델에서 정확한 예측을 하기 위해 필요합니다. 각 클래스에 대한 예측 값과 실제 값의 차이를 계산하여 손실 함수를 최소화합니다.당신이해야하기 때문에
Pytorch에서 BCELoss, BCEWithLogitLoss 및 CrossEntropyLoss의 차이점
BCELoss(이진 교차 엔트로피 손실)
BCELoss는 각 클래스의 확률을 독립적으로 계산하는 이진 분류 문제에 사용되는 손실 함수입니다. 예측 확률과 실제 레이블 간의 차이를 최소화하는 데 사용됩니다. BCELoss를 사용하기 전에 모델의 출력을 시그모이드 함수를 통해 0과 1 사이의 확률 값으로 변환해야 합니다.
import torch
import torch.nn as nn
# 예측 확률 및 실제 레이블
predictions = torch.tensor(((0.8, 0.3), (0.1, 0.9)), requires_grad=True)
labels = torch.tensor(((1.0, 0.0), (0.0, 1.0)))
# Sigmoid 함수 적용
sigmoid = nn.Sigmoid()
predictions = sigmoid(predictions)
# BCELoss 사용
bce_loss = nn.BCELoss()
loss = bce_loss(predictions, labels)
loss.backward()
BCEWithLogitsLoss
BCEWithLogitsLoss는 모델의 출력이 시그모이드 함수를 통해 확률 값으로 변환되는 BCELoss의 변형입니다. 이 손실 함수는 이진 분류 문제에 사용되며 BCELoss보다 수치적으로 더 안정적입니다.
import torch
import torch.nn as nn
# 로짓 및 실제 레이블
logits = torch.tensor(((1.2, -0.5), (-2.0, 0.8)), requires_grad=True)
labels = torch.tensor(((1.0, 0.0), (0.0, 1.0)))
# BCEWithLogitsLoss 사용
bce_logits_loss = nn.BCEWithLogitsLoss()
loss = bce_logits_loss(logits, labels)
loss.backward()교차 엔트로피 손실
CrossEntropyLoss는 다중 클래스 분류 문제에 사용되는 손실 함수입니다. 이 함수는 모델의 출력을 softmax 함수에 의해 확률 값으로 변환한 후 실제 레이블과의 차이를 최소화하기 위해 사용됩니다. CrossEntropyLoss에는 softmax 함수가 포함되어 있으므로 모델의 출력을 직접 전달하면 됩니다.
import torch
import torch.nn as nn
# 로짓 및 실제 레이블
logits = torch.tensor(((1.2, 0.5, -0.8), (-0.5, 0.8, 2.0)), requires_grad=True)
labels = torch.tensor((0, 2))
# CrossEntropyLoss 사용
cross_entropy_loss = nn.CrossEntropyLoss()
loss = cross_entropy_loss(logits, labels)
loss.backward()요약하면 각 손실 함수의 차이점은 다음과 같습니다.
1. BCELoss: 이진 분류 문제에 사용되며 모델 출력에 시그모이드 함수를 적용한 후 사용해야 합니다.
2. BCEWithLogitsLoss: 이진 분류 문제에 사용되며 모델 출력을 직접 사용하고 내부적으로 시그모이드 함수를 적용합니다. 수치적으로 안정적입니다.
3. CrossEntropyLoss: 다중 클래스 분류 문제에 사용되며 모델 출력을 직접 사용하고 내부적으로 softmax 함수를 적용합니다.
문제에 따라 적합한 손실 함수를 선택하여 사용할 수 있습니다. 이진 분류 문제의 경우 BCEWithLogitsLoss를 사용하는 것이 좋습니다. 다중 클래스 분류 문제의 경우 CrossEntropyLoss를 사용할 수 있습니다.