아래 영상을 보고 작성한 글입니다.
정규화란 무엇인가
– 데이터 중복을 제거하기 위해 관계를 분해하는 과정입니다.
예)
기능 종속성
{학번,과목} -> 성적
입학번호 -> 지도교수
입학번호 -> 학과
컨설턴트 -> 부서
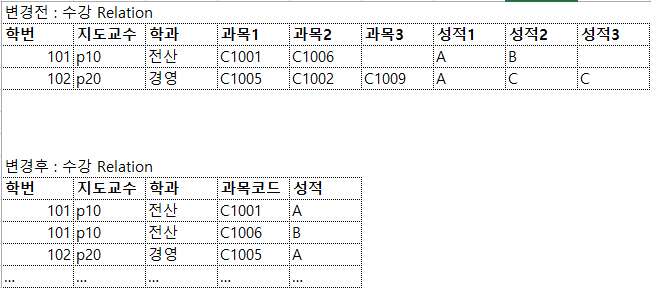
제1정규형: 비원자 도메인(속성) 분해(겹치는 속성이 원자 값을 가질 때까지 분해)
– 비원자 도메인 분해 –> 정규형 1개 만족
– 중복 속성을 제거합니다.
– 릴레이션 R에 속하는 모든 모드가 원자 값으로 구성되어 있으면 1NF(첫 번째 일반 문자열)가 충족됩니다.

제2정규형: 함수 의존성의 부분적 제거
– 기본키를 중심으로 의존성이 없는 경우
– (B -> C) BC가 결정하는 경우(B: 결정자, C: 종속)

3. 정규형: 전달 함수의 종속성 제거(전달).
– (E -> F) EF가 결정하면 (E: 결정자, F: 종속)

BCNF(Boyce-Codd Normal Form): 결정자가 후보 키가 아닌 함수 종속성 제거
예)
기능 종속성
{입학번호, 과목} -> 교수
교수 -> 과목
– (D->A) DA가 결정하는 경우(D: 결정자, A: 종속)
–> 결정자가 후보 키가 아닌 함수를 제거합니다.
–> 결정자가 후보 키가 아니고 종속 키가 기본 키의 하위 집합인 속성 분해
– A는 부분 기본키이지만 BCNF가 발생하면 B만 기본키로 남게 되므로 재구성을 위해 테이블 속성과 속성 속성을 다시 확인한다.
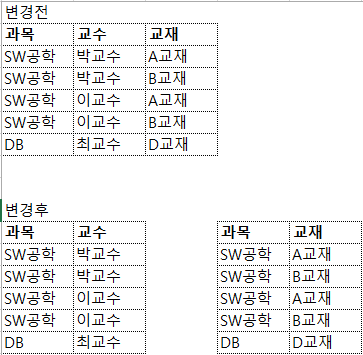
제4정규형: 다중 종속성 제거
– 관계 R에 속성 A ->> B가 존재하는 경우 모든 속성이 속성 A에 종속되도록 분해(A를 기준으로 분해)
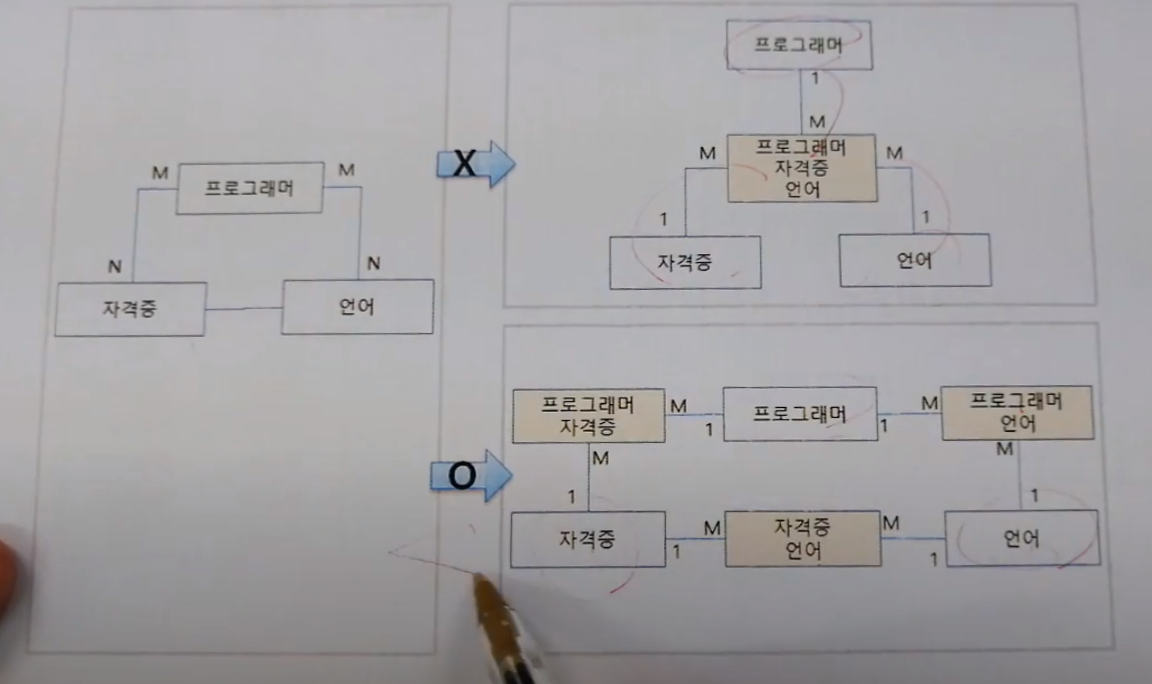
다섯 번째 정규형: 후보 키와의 조인 종속성을 제거하지 마십시오.
– 조인에 의한 원래 검색은 릴레이션 R이 3개로 쪼개진 경우에만 가능합니다.